🥨 Bretzel Craft 2026 : Première édition !
Le 12 février 2026 a eu lieu la 1ère édition de Bretzel Craft à Strasbourg ! Cet article propose un retour sur la track des formats long de la journée


J’ai eu le plaisir d’assister à la 1ère édition de Bretzel Craft, nouvelle conférence technique à Strasbourg, initiée par le meetup Strasbourg Craft et portée notamment par Edouard Mangel et Marc Bouvier. Un grand bravo à eux pour cette première édition réussie, et un grand merci pour l’énergie mise dans l’organisation. Hâte de pouvoir revenir à la suivante ! Pour les intéressés, vous pouvez d’ores et déjà retrouver les captations des différentes présentations sur la chaîne YouTube du meetup.
Ayant habité à Strasbourg puis à proximité de Lyon, j’ai eu l’occasion de retrouver beaucoup de têtes que je connaissais : anciens collègues, développeurs actifs aux événements strasbourgeois, ainsi que quelques personnes du meetup Crafter Lyon qui avaient fait le déplacement. C’était très sympa, et ce mélange a vraiment contribué à l’ambiance de la journée.
La journée a démarré avec une courte introduction d’Edouard, avant de laisser la place à Houleymatou Baldé, fondatrice de Yeeso et du réseau IT Women Network, pour une keynote d’ouverture inspirante. Elle y a raconté un parcours miné d’obstacles et comment, contre le destin, elle a toujours réussi à les contourner pour avancer.
"The Black Box Bare Test" : jusqu’où l’IA peut-elle nous "remplacer" au travail ?
Pendant ces 2h d’atelier, Christophe nous met face à un challenge : à travers un scénario, on doit comprendre un programme dont on a les sources, afin de répondre à une série de questions sur son utilité, son fonctionnement et ses limites.
Problème : les sources sont en C++, volontairement compliquées à lire, avec aussi de l’assembleur. Le C++ sert surtout de code d’émulation, tandis que la logique métier tourne dans un assembleur 6502, un microprocesseur rudimentaire. Heureusement, on a le droit de s’aider de l’IA, et c’est tout le concept de l’atelier : voir jusqu’où elle peut nous aider, et surtout ce qui reste du rôle du/de la développeur·se.
Christophe partage sa définition du métier en 10 actes. Sans tout recopier ici, j’en retiens surtout quatre idées :
- Clarifier les objectifs, les contraintes et les difficultés du problème
- Prévenir les défauts et chercher les problèmes avant l’usage réel
- Modéliser, versionner et documenter les décisions structurantes
- Communiquer, apprendre en continu, puis livrer
On remarque qu’aucun de ces points ne parle de "produire du code" au sens strict. Le développeur orchestre objectifs, contraintes et décisions, et l’IA l’assiste sans vision d’ensemble. Dans cette vision, l’IA ne remplace pas l’humain.
L’objectif du challenge est de démontrer cette idée dans la pratique. Il s’agissait de la 4e session que Christophe organisait. Lors des 3 premières, les participants n’avaient pas réussi à remplir tous les objectifs, voire s’en étaient détournés. Pour éviter de se perdre, il animait la séance en nous poussant à partager nos découvertes.
Une fois le projet cloné, on est un peu déboussolés. On n’a quasiment aucune indication, ne serait-ce que pour savoir comment lancer le programme. La quinzaine de personnes présentes expérimentent différentes approches, avec ou sans IA. Les premiers signaux que l’on obtient sont les suivants :
- Le binaire renvoie très souvent “X” après validation d’un input
- Les entrées par blocs de 4 nombres donnent des sorties qui semblent structurées, mais difficiles à interpréter
- On observe aussi des bornes sur certaines valeurs
À partir de là, certaines IA lancées depuis 15-20 min ont fait drastiquement avancer la compréhension, avec un prompt simple de découverte du projet et de création d’un fichier de contexte. En testant de nombreux inputs et en analysant le code, l’une d’elles a même réussi à reconnaître que le programme cherchait à résoudre un problème d’optimisation de planning, où les séries de 4 nombres correspondent à un id, une date de début, une durée et une valeur de tâche.
Pour autant, il restait des zones d’ombre à éclaircir, et des tests à faire pour bien comprendre les limites du programme. On a notamment eu un long débat sur un possible bug de gestion des années bissextiles remonté par l’IA. Au final, il n’y avait pas de bug exploitable dans le périmètre du challenge, car la plage de dates empêchait le cas de se produire.
Un point marquant de l’atelier est que, même avec l’IA, le programme reste compliqué à modifier. On garde peu de contrôle sur ce qu’elle fait réellement, et cela demande une confiance presque aveugle.
Suite à l’atelier, j’ai eu envie de continuer l’exercice pour tester ce qu’il était réellement possible de modifier avec l’IA. J’ai d’abord supervisé la mise en place d’une batterie de tests pour limiter les régressions, puis j’ai tenté quelques changements :
- Afficher “Invalid Input” au lieu de “X”
- Augmenter la période maximale du calendrier (année max 99 -> 100 000)
- Gérer les cas particuliers des années bissextiles (inactifs en dessous de l’année 100)
- Faire renvoyer la liste des tâches sélectionnées, et pas uniquement la valeur maximale
Cette dernière modification a été la plus instructive. En lui demandant un plan, l’IA m’a proposé deux pistes, toucher le code C++ de l’émulateur ou intervenir au niveau du code assembleur 6502 émulé. J’ai tranché pour la seconde. Sans les sources assembleur, elle revenait souvent vers la solution simple en dupliquant ou en remplaçant la logique métier côté émulateur. J’ai dû recadrer deux fois pour qu’elle suive le plan. Au final, la modification a abouti, probablement grâce à une forme de décompilation puis de rétro-ingénierie du binaire.
L’ajout de tests apporte de l’assurance sur le comportement visible, mais on reste relativement aveugles sur la manière dont l’IA gère les changements en interne. Cette itération m’a surtout rappelé que, sans cadrage strict, l’IA peut vite aller à l’encontre des consignes. Et sur un sujet qu’on ne maîtrise que partiellement, on peut perdre la main très vite.
J’ai beaucoup aimé cet atelier, et nous étions le premier groupe à réussir à le compléter grâce aux avancées récentes de l’IA. On a toutefois été aidés par le fait que le problème résolu est assez simple et connu. Sur un projet de grande envergure, ce serait probablement une autre histoire. Christophe a conclu qu’il allait revoir l’exercice pour les prochaines sessions, afin de redonner un peu plus de piment à la résolution.
Cynefin : mettre des mots sur la complexité pour mieux la gérer
Cynefin est un framework dont le but est d’aider à catégoriser les problèmes (dans le sens tâches à effectuer), afin d’y répondre avec le type de solution adapté. Son but n’est pas de trouver des solutions à nos problèmes, seulement d’éviter d’être dans la douleur face à un problème que l’on approcherait de la mauvaise manière.
Le point qui m’a le plus marqué dans ce talk, c’est que l’enjeu n’est pas de "bien exécuter", mais d’abord de comprendre à quel type de problème on a affaire. Sinon, on tombe vite dans deux douleurs classiques : se prendre des murs et accumuler les échecs, ou appliquer des process trop lourds sur un problème finalement simple.
Romeu insiste aussi sur le fait que c’est notre perception qui se situe dans un domaine, pas le problème "en soi". Un même sujet peut être complicated pour une personne et clear pour une autre, et cette perception peut évoluer avec le temps.
Dans la présentation, les catégories sont abordées comme suit :
Clear: problème prédictible, exécution simple, peu d’inconnuComplicated: problème analysable, estimable, qui demande expertise et réflexionComplex: trop de paramètres pour prédire proprement, progression par expérimentation, tâtonnage et itérations rapidesChaos: on ne peut pas faire sens du problème immédiatement, il faut d’abord agir pour reprendre la mainConfusion: on ne sait pas dans quel domaine on se trouve, ou on se trompe de domaine, et c’est souvent douloureux car on applique une approche inadaptéeComplacency: catégorie souvent oubliée selon Romeu, liée à l’accumulation de sujetsclearnégligés qui finissent par basculer vers ducomplexou duchaos
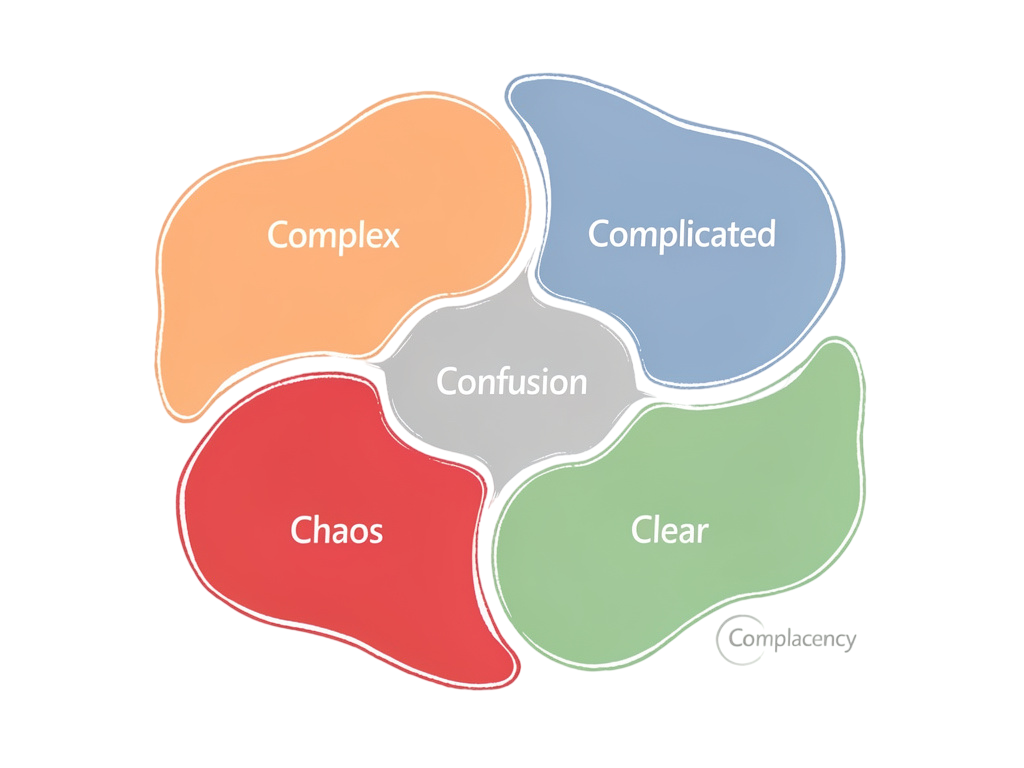
Un point utile au passage : plus on est bon en rétrospective et en apprentissage sur nos erreurs, plus on réduit la zone de chaos au profit de complex.
L’autre point que j’ai trouvé vraiment intéressant, c’est la tension entre l’entreprise et les devs. Les entreprises cherchent du prédictible pour construire des bilans solides. Les devs, eux, ont souvent envie d’éviter le trop prévisible, parce que c’est vite automatisable et peu stimulant. Le piège, c’est que personne n’aime vraiment le complex, alors que c’est précisément là qu’on se retrouve régulièrement.
Pour ma part, ce cadrage m’a surtout fait penser au lean startup. En terrain complex, estimer est souvent inutile. Ce qui aide, c’est d’itérer vite pour apprendre vite et ajuster. C’est d’ailleurs ce qu’on essaye de faire chez Wanteeed, et ça a bien fait écho avec notre lecture en cours de The Lean Startup. Romeu pointe aussi l’intérêt de construire des groupes plus autonomes en compétences, pour faire passer certains sujets de complex à complicated.
TDD, au-delà de l'intro
Dans cette deuxième présentation-discussion, Romeu partage ses approches du TDD en précisant bien que ce ne sont pas des prescriptions universelles, mais des pratiques qui fonctionnent pour lui. Pour illustrer, il s’appuie sur le célèbre kata Fizz Buzz.
Il commence par un rappel utile du cadre TDD : cycle “Red, Green, Refactor”, itérations courtes (babysteps), principe YAGNI (“You aren’t gonna need it”), et devise “Make it work, Make it right, Make it fast”.
J’ai regroupé ses conseils en trois familles.
1) Repousser certains choix de design
TDD as you mean it pousse à écrire d’abord l’implémentation future dans le fichier de test, ce qui permet de repousser certaines décisions de structure.
Lazy naming va dans le même sens : nommer plus tard, quand on comprend mieux ce qu’on est en train de faire, plutôt que figer trop tôt un vocabulaire imparfait.
2) Rigueur des tests, sobriété du code
On retrouve une idée assez classique en TDD : rester de bonne foi côté tests, et accepter une forme de “mauvaise foi” côté implémentation pour faire le strict nécessaire qui passe.
Puis revenir rapidement à un refactor de bonne foi, Romeu évoque l’idée d’enchaîner quelques cycles courts avant de nettoyer (de l’ordre de 3 cas dans son approche).
Il mentionne aussi le property-based testing comme piste pour éviter certains angles morts. Il l’évoque plutôt comme une piste à explorer que comme un point détaillé pendant le talk. L’idée est de formuler des règles générales que le code doit toujours respecter, puis de générer automatiquement un grand nombre d’entrées, y compris des cas limites, au lieu d’écrire chaque cas à la main. Pendant l’écriture, Romeu propose de suivre des “branches logiques” quand on a l’instinct de ce regroupement, par exemple traiter d’abord le cas normal, puis les cas fizz, buzz et fizzbuzz. Et si cet instinct n’est pas là, on avance sans forcer ce découpage, puis on regroupe plus tard via refacto.
3) Faire des tests qui expliquent le métier
La partie que j’ai trouvée la plus intéressante à titre personnel concerne l’organisation des tests. L’idée n’est pas seulement d’avoir un filet de sécurité technique. Romeu assume aussi des tests parfois redondants techniquement, parce qu’ils portent des cas métier différents. Sur Fizz Buzz, ça revient à garder visibles des tests séparés pour cas normal, fizz, buzz et fizzbuzz, même si on pourrait factoriser davantage. Cette redondance aide la personne qui lit la suite à s’imprégner des règles métier.
Ensuite, l’ordre final des tests peut être réorganisé pour maximiser la compréhension, avec une logique d’archéologie du code pour les futures personnes qui liront la suite. Le but n’est pas de raconter l’ordre historique d’écriture, mais d’offrir un parcours de lecture qui fait émerger les règles progressivement.
Sur le nommage, il défend des tests lisibles comme des phrases, avec la formule “In English you can verb anything”. Exemple donné en Java : classe FizzBuzzShould avec une méthode fizz_on_(int a_multiple_of_3).
Romeu rappelle aussi que le développement est une activité intellectuelle. Refaire une solution une deuxième fois peut coûter moins cher que d’essayer de faire “parfait” du premier coup.
Au final, j’ai surtout retenu ses conseils d’organisation des tests. Je me projette moins sur les pratiques qui impliquent de garder longtemps des noms temporaires ou de jeter beaucoup de travail. Son parallèle entre plotters et pantsers éclaire bien ce décalage. Les plotters planifient beaucoup avant d’écrire, les pantsers écrivent plus vite et retravaillent davantage ensuite. Il n’y a pas de meilleure approche en soi, plutôt des manières de fonctionner différentes. Lui se revendique plutôt pantser, alors que je me reconnais davantage dans une posture plotter.