Dans les coulisses de la donnée chez Wanteeed


Comment on a construit une stack data en temps réel, fiable et scalable.
Chez Wanteeed, notre mission est claire : faire gagner de l’argent à nos utilisateurs grâce au cashback et aux codes promo. Mais derrière cette promesse visible, il y a un autre moteur, moins glamour mais tout aussi essentiel : la donnée.
Car pour servir des millions d’utilisateurs, tester des features en continu, afficher des stats personnalisées en temps réel ou entraîner des modèles prédictifs... il faut une stack data robuste, fiable et modulable.
Dans cet article, je vous partage comment on a construit notre architecture de données : les outils, les choix techniques, les arbitrages humains, les erreurs aussi — bref, ce qui fait qu'aujourd’hui, la donnée est un moteur de notre produit, pas un sous-système secondaire.
🧭 Vue d’ensemble de notre modern data stack:
Avant d’entrer dans les détails, voici une vision simplifiée de notre architecture.
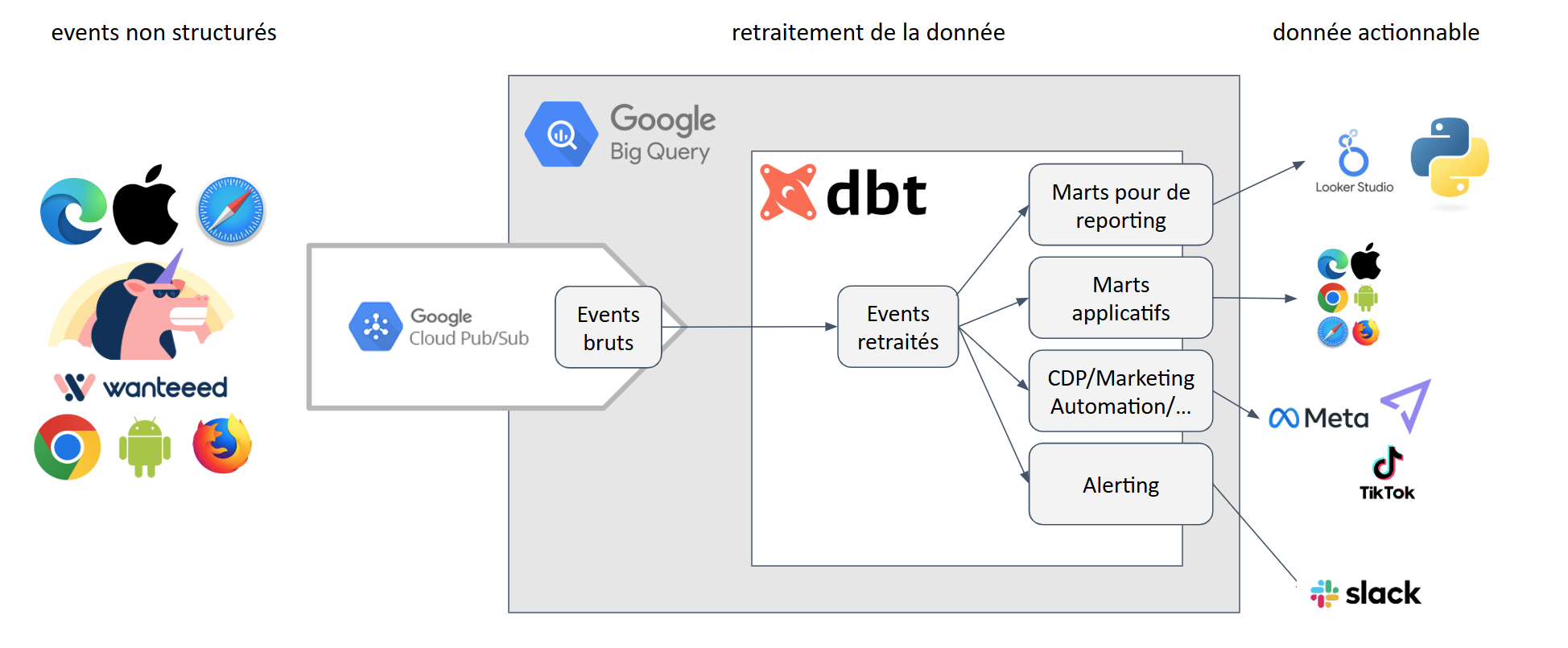
Les données arrivent depuis nos différents services sur BigQuery pour être transformées en données actionnables par les outils consommant la donnée.
1️⃣ La collecte : suivre l’utilisateur sans le perdre
Tout commence sur nos produits : un clic sur un marchand, un cashback activé, un code promo appliqué. Chaque interaction génère un événement non structuré, qu'on pousse dans Google Pub/Sub.
Pourquoi on a choisi Pub/Sub?
- Un endpoint unique pour plusieurs sources de données
- Pousse les événements nativement dans BigQuery
- Tient une charge importante lorsque le trafic explose lors de gros événements e-commerce comme le Black Friday
2️⃣ BigQuery : une base de données qui stocke et transforme
Les événements sont ensuite stockés bruts dans BigQuery. Il y a très peu d'architecture en place dans BigQuery. Bien qu'on y trouve beaucoup d'outils pour transformer ou exploiter les données, nous architecturons et orchestrons 95% de nos requêtes SQL via DBT.
Pourquoi on a choisi BigQuery ?
- Pas d’infra à gérer : pas de clusters, pas de stress, tout a un historique, tout (ou presque) est réparable
- Très bon support des jointures et analyses volumineuses
- Intégré naturellement dans notre stack GCP
- Et avec la tarification à la requête, qui permet de contrôler le coût de chaque opération, ce qui permet un reporting détaillé par fonctionnalité produit
On parle ici de plusieurs millions d’événements par jour, il nous faut donc une base de données qui permette de manipuler un gros volume sans devoir constamment optimiser calculs et coûts (souvent liés).
3️⃣ DBT : le chef d'orchestre
C’est ici que la magie opère.
Nous utilisons DBT (Data Build Tool) pour transformer nos événements bruts en données exploitables : enrichies, fiables, documentées, testées.
DBT a le rôle de faire exécuter des requêtes SQL dans BigQuery et d'y stocker les résultats.
Ce qu’on fait avec DBT :
- Nettoyer : correction des valeurs aberrantes, suppression des doublons, uniformisation des formats, harmonisation des valeurs, etc.
- Enrichir : compléter des informations qui seraient manquantes, ajouter du contexte, etc.
- Modéliser : construire des tables qui pour les différents outils qui vont consommer les données
🛠️ Tout est versionné sur GitHub. Chaque PR déclenche un pipeline CI/CD :
- Tests unitaires (❤️)
- Vérifications de qualité (présence de NULLs, duplication)
- Documentation automatique
- Lineage
👉 Ce process nous garantit des modèles robustes, même quand plusieurs équipes poussent des changements en parallèle. Ca permet également aux développeurs de contribuer à nos modèles DBT, et à faire évoluer la documentation ou architecture en fonction des propriétés ou events qu'ils implémentent.
4️⃣ Batch vs Streaming : une consommation à deux vitesses
Nous avons structuré notre pipeline autour de deux temporalités :
⚡ Temps réel :
- Pour les statistiques affichées/consommées aux utilisateurs (ex : proposer les derniers codes promos disponibles)
- Les tests A/B (en temps réel pour monitorer les fonctionnalités introduites)
- Les alertes opérationnelles (ex : chute soudaine des activations cashback).
On peut analyser les events en sortie de Pub/Sub dans leur format le plus brut. On ne passera souvent pas par DBT pour les besoins de streaming, on essaye de garder le calcul au plus proche du consommateur pour limiter les nombre d'outils dans ce contexte de temps réel.
🕓 Batch quotidien :
- Modèles plus complexes (attribution, nettoyage avancé, hydratation de données plus anciennes)
- Agrégats pour le reporting, modèles de ML, automatisations quotidiennes
- Alertes nécessitant un large historique (ex: "le % de réduction obtenu par les utilisateurs est anormalement bas sur ce marchand")
5️⃣ Des données pour tous les usages
On ne fait pas tout ça “juste pour le fun” (même si j'adore ça) : chaque brique data sert un objectif concret.
➤ Pour les équipes Produit :
- Données disponibles dans Indicative, Looker, Google Sheet pour d'autres
- Possibilité de segmenter les utilisateurs en fonction de leur comportement
- Construction de funnel, analyse du churn, s'assurer du bon fonctionnement
➤ Pour les utilisateurs :
- Plus d'économies car on a des retours quantitatifs à amener à nos équipes tech et à nos partenaires
- Une meilleure UX qui correspond à leurs besoins
- Une gestion des données personnelles facilitée
➤ Pour les analystes et le marketing :
- Datamarts agrégés pour un usage plug-and-play sur les outils de visualisation
- Une facilité pour la mise à disposition de la donnée à disposition des autres outils
➤ Pour la data science :
- Agilité, puissance de calcul de BigQuery
- Intégration native de fonctionnalité de ML, en SQL ou Python
🚧 Les challenges qu’on continue d’adresser
🔍 Maintenir une qualité irréprochable
- Sur le batch, c’est facile : tu peux rejouer, même si ça peut vite coûter cher.
- Sur le streaming, c’est une autre histoire. Mais ça nous force à remplir nos events le plus possible dès l'envoi pour se reposer le moins possible sur le retraitement
On a mis en place des tests légers mais fréquents pour monitorer la donnée en temps réel : taux de remplissage, validité des clés, latence.
✅ Ce qu’on a appris
Construire une stack data moderne, ce n’est pas empiler des outils. Cela consiste à:
- Mettre l’automatisation au service de la qualité,
- Accepter que tout ne peut pas être parfait tout de suite,
- Travailler main dans la main avec les équipes produit, tech, marketing
- Et surtout, garder l’utilisateur final et son besoin en ligne de mire.
Chez Wanteeed, la donnée n’est pas un produit dérivé. C’est un levier produit à part entière.